
Unpredictable Black Boxes are Terrible Interfaces
Why generative AI tools can be so difficult to use and how we might improve them

I recently decided I should update the profile picture on my webpage.

As a Computer Science Professor, I figured the easiest way to produce a high-quality photo would be to generate it using DALL-E2. So I wrote a simple prompt, “Picture of a Professor named Maneesh Agrawala” and DALL-E2 made an image that is … well … stunning.
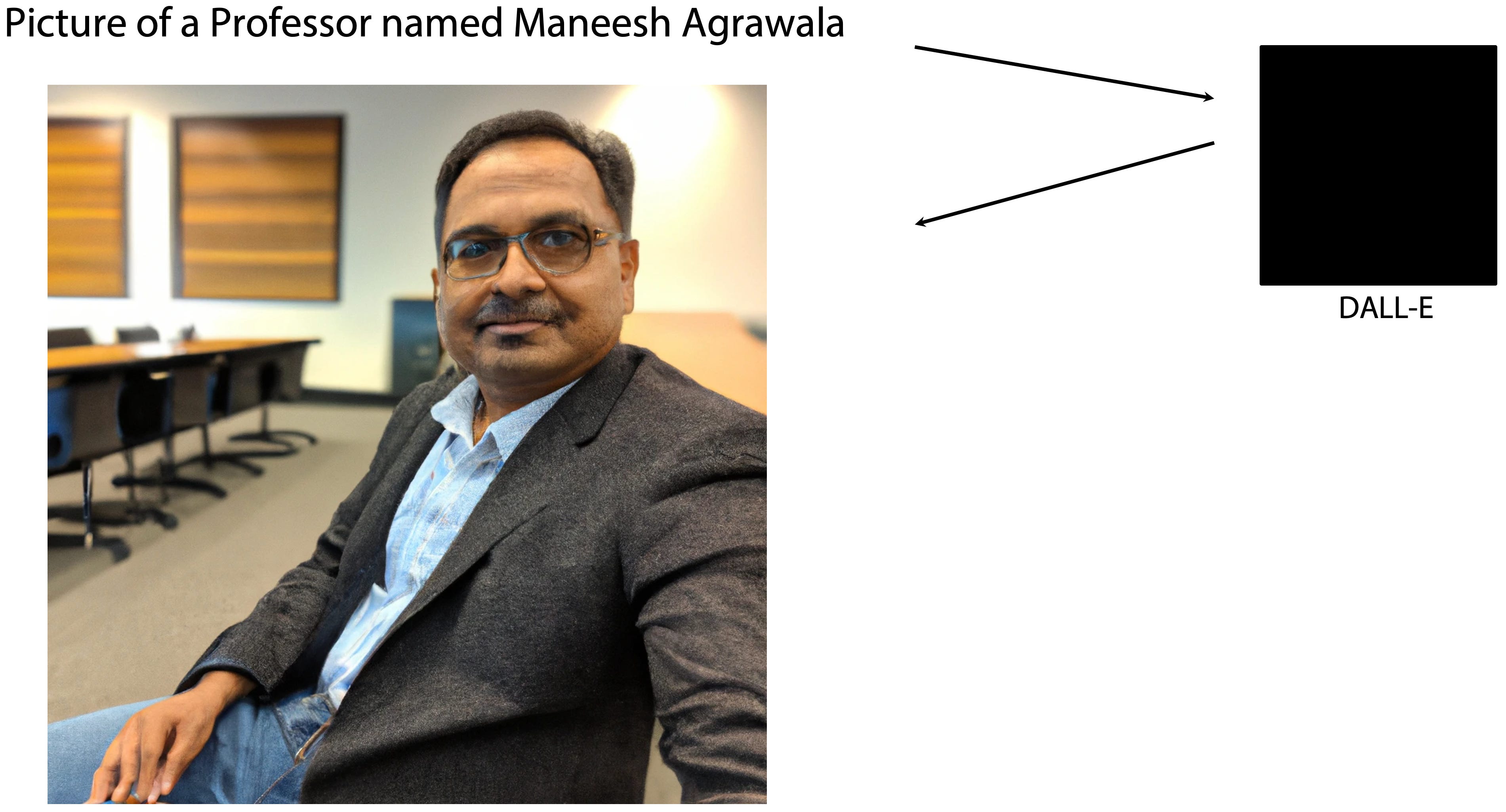
From the text prompt alone it generated a person who looks to be of Indian origin, dressed him in “professorly” attire and placed him in an academic conference room. At a lower level, the objects, the lighting, the shading and the shadows are coherent and appear to form a single unified image. I won’t quibble about the artifacts — the fingers don’t really look right, one temple of the glasses seems to be missing and of course I was hoping to look a bit cooler and younger. But overall, it is absolutely amazing that a generative AI model can produce such high-quality images, as quickly as we can think of prompt text. This is a new capability that we have never had before in human history.
And it is not just images. Modern generative AI models are black boxes that take a natural language prompt as input and transmute it into surprisingly high-quality text (GPT-4, ChatGPT), images (DALL-E2, Stable Diffusion, Midjourney), video (Make-A-Video), 3D models (DreamFusion) and even program code (Copilot, Codex).


So let’s use DALL-E2 to make another picture. This time I’d like to see what Stanford’s main quad would look like if it appeared in the style of the film, Blade Runner. When I think of Stanford’s main quad I think about the facade of Memorial Church and palm trees. When I think I of Blade Runner, I think of neon signs, crowded night markets, rain, and food stalls. I start with a simple prompt, “stanford memorial church with neon signage in the style of bladerunner”.

At this first iteration the resulting images don’t really show the Stanford quad with its palm trees. So I first add “and main quad” to the prompt for iteration 2 and after inspecting those results I add “with palm trees” for iteration 3. The resulting images look more like the Stanford quad, but don’t really look like the rainy nighttime scenes of Blade Runner. So I cyclically revise the prompt, inspect the DALL-E2 generated images and then update the prompt, to try and find a combination of prompt words that produce something like the image I have in mind. At iteration 21, after several hours of somewhat randomly trying different prompt words, I decide to stop.

The resulting image isn’t really what I had in mind. Even worse, it is unclear to me how to change the prompt to move the image towards the image I want. This is frustrating.
In fact, finding effective prompts is so difficult that there are websites and forums dedicated to collecting and sharing prompts (e.g. PromptHero, Arthub.ai, Reddit/StableDiffusion). There are also marketplaces for buying and selling prompts (e.g. PromptBase). And there is a cottage industry of research papers on prompt engineering.
Good interfaces provide a predictive conceptual model
To understand why writing effective prompts is hard, I think it is instructive to remember an anecdote from Don Norman’s classic book, The Design of Everyday Things. The story is about a two-compartment refrigerator he owned, but found extremely difficult to set the temperature for properly. The temperature controls looked something like this:

Separate controls for the freezer and fresh food compartments suggest that each one has its own independent cooling unit. But this conceptual model is wrong. Norman explains that there is only one cooling unit; the freezer controls sets the cooling unit’s temperature while the fresh food control sets a valve that directs the cooling to the two compartments. The true system model couples the controls in complicated way.

With an incorrect conceptual model users cannot predict how the input controls produce the output temperature values. Instead they have to resort to an iterative, trial-and-error process of (i) setting the controls, (ii) waiting 24 hours for the temperature to stabilize and (iii) checking the resulting temperature. If the stabilized temperature is still not right they must going back to step (i) and try again. This is frustrating.
For me there are two main takeaways from this anecdote.
Well designed interfaces let users build a conceptual model that can predict how the input controls affect the output.
When a conceptual model is not predictive, users are forced into using trial-and-error.
The job of an interface designer is to develop an interface that lets users build a predictive conceptual model.
AI black boxes do not provide a predictive conceptual model
Generative AI black boxes are terrible interfaces because they do not provide users with a predictive conceptual model. It is unclear how the AI converts an input natural language prompt into the output result. Even the designers of the AI usually can’t explain how this conversion occurs in a way that would allow users to build a predictive conceptual model.
I went back to DALL-E2 to see if I could get it to produce an even better picture of me, using the following prompt, “Picture of a cool, young Computer Science Professor named Maneesh Agrawala”.

But I have no idea how the prompt affects the picture. Does the word “cool” produce the sports coat and T-shirt combination, or do they come from the word “young”? How does the term “Computer Science” affect the result? Does the word “picture” imply the creation of a realistic photograph rather than an illustration? Without a predictive conceptual model I cannot answer these questions. My only recourse is trial-and-error to find the prompt that generates the image I want.
Humans are also terrible interfaces, but better than AI
One goal of AI is to build models that are indistinguishable from humans. You might argue that natural language is what we use to work with other humans and obviously humans are good interfaces. I disagree. Humans are also terrible interfaces for many generative tasks. And humans are terrible for exactly the same reasons that AI black boxes are terrible. As users we often lack a conceptual model that can precisely predict how another human will convert a natural language prompt into output content.

Yet, our conceptual models of humans are often better (more predictive) than our conceptual models of AI black boxes, for two main reasons. First, our conceptual model of the way a human collaborator will respond to a prompt is likely based on the way we ourselves would respond to the request. We have strong prior for the conceptual model as we assume that a human collaborator will act similarly to the way we would act. Second, as psycholinguists like Herb Clark have pointed out, we can converse with a human collaborator to establish common ground and build shared semantics. We can use repair strategies to fix ambiguities and misunderstandings that arise in natural language conversations. Common ground, shared semantics and repair strategies are fundamental for collaboration between humans.
Yet, despite these advantages, working with another human to generate high-quality content often requires multiple iterations. And the most effective collaborations often involve weeks, months, or even years of conversation to build the requisite common ground.
As I said, humans are terrible interfaces. But they are better than AI black boxes.
With AI, our conceptual models are either non-existent or worse, they are based on the prior we have for human collaborators. We assume the AI will generate what a human collaborator might generate given the prompt. Unfortunately, this type of anthropomorphization is difficult to avoid. Claims that an AI model “understands” natural language or that it has “reasoning” capabilities, reinforce that the idea that the model somehow understands and reasons the way a human understands and reasons. Yet, it is almost certainly the case that AI does not understand or reason about anything the way a human does.
Towards generative AI with conversational interfaces
So how can we make better generative AI tools? One way might be to support conversational interactions. Text generation tools like ChatGPT are already starting to do this. Such tools support conversational turn-taking and can treat earlier exchanges as context for future exchanges. The context lets both the AI and the user refer to concepts mentioned earlier in the conversation and thereby enables a kind of shared common ground. But it is unclear how much common sense knowledge such systems contain and the grounding of semantic concepts seems rather shallow. For users it is unclear what ChatGPT knows and what it doesn’t know, so conversations can require multiple turns just to establish basic shared facts. Moreover, the conversational interaction with a user doesn’t update the AI model so the AI cannot learn new concepts from the user. Adding common sense, grounding and symbolic reasoning to these models remains a major thrust of ongoing AI research.

Natural language is often ambiguous. In conversations, people use repair strategies to reduce such ambiguity and ensure that they are talking about the same thing. Researchers have started to build such repair mechanisms into text-to-image AI systems. For example, Prompt-to-Prompt image editing [Hertz 2022] is a technique that lets users generate an image from an initial text prompt and then refine the prompt to produce a new image but with only a minimal set of changes required to reflect the edited prompt. An initial prompt of “a cake with decorations” might be refined to “a cake with jelly bean decorations” and the initial image would be updated accordingly. Such refinement is a form of repair.

Another way to reduce the ambiguity of natural language is to let users add constraints as conditioning on the generation process. Image-to-image translation [Isola 2016] showed how to apply this approach in the context of image synthesis. It converts one type of input image (e.g. a label map, an edge image, etc.) into another type of image (e.g., photograph, a map, etc.) by learning a generative adversarial network (GAN) conditioned on the input image type. The input image imposes spatially localized constraints on the composition of the output image. Such input images are effective controls, because it is much easier for users to specify precise spatial composition using imagery rather than spatially ambiguous natural language. Recently, we and many other groups have applied this approach in the context of text-to-image AI models.

Conversational interactions can also go beyond natural language. In the context of text-to-image AI models, researchers have started to develop methods that establish common ground. Textual Inversion [Gal 2022] and DreamBooth [Ruiz 2022] let users provide a few example images of an object and the AI model learns to associate a text token with it (both methods fine-tune a diffusion model using the example images). When users put the learned token in a new prompt, the system includes the corresponding object into the image. Thus the user and the system build a kind of shared grounding for the object.

Neurosymbolic methods may provide another path to a conversational interface with AI models. Consider a generative AI model that instead of directly outputting content, outputs a program which must be executed to produce the content. The advantage of this approach is that the output program is something that both humans and the AI model might be able to understand in the same way. It may be possible to formalize the semantics of the programming language in ways that allows for shared understanding between the a human developer and the AI. Even without formal semantics, the human developer might be able to inspect the code and check that the code is doing “the right thing”. And when the code fails, the developer might be able to suggest fixes to the AI in the programming language itself rather than relying on natural language input alone. This approach is essentially about shifting the language for communicating with the AI from human natural language to something closer to a programming language.
Takeaways
Generative AI models are amazing and yet they are terrible interfaces. When users cannot predict how input controls affect outputs they have to resort to trial-and-error, which is frustrating. This is a major issue when using generative AI for creating new content and it will remain an issue as long as the mapping between the input controls and outputs is unclear. But we can improve AI interfaces by enabling conversational interactions that can let users establish common ground/shared semantics with the AI, and that provide repair mechanisms when such shared semantics are missing.
This post is a revised and updated version of a talk I gave at the HAI 2022 Fall Conference on AI in the Loop: Humans in Charge. Thanks to Michael Bernstein, Jean-Peïc Chou, Kayvon Fatahalian, James Landay, Jeongyeon Kim, Jingyi Li, Sean Liu, Jiaju Ma, Jacob Ritchie, Daniel Ritchie, Ben Shneiderman, Lvmin Zhang and Sharon Zhang for providing feedback on the ideas presented here.
Maneesh Agrawala (@magrawala, @magrawala@fediscience.org) is a cool, young Computer Science Professor and Director of the Brown Institute for Media Innovation at Stanford University. He is on sabbatical at Roblox.
Thanks for this great article!
Like ChatGPT made the model a lot more powerful because it was usable, further study on interfaces with AI models will lead to larger impact of them.
Thanks Maneesh for articulating some of the frustrations people are having with these systems! Completely agree that UI is one of the important features of doing generative AI well. The other two for me are data and verification. You can read more in my post here - https://embracingenigmas.substack.com/p/why-your-generative-ai-startup-will. Happy to collaborate if you are interested.